
TPU 8t和TPU 8i具備專為訓練和推論打造
Google強調,第8代Google客製化TPU,具備專為訓練和推論打造的兩種截然不同架構:TPU 8t和TPU 8i。這兩款專門打造的晶片旨在重新定義AI的可能性,從建立最強大的AI模型,到完美調度龐大的AI代理群,以及管理最複雜的推理任務。
Google資深副總裁兼人工智慧與基礎設施首席技術專家Amin Vahdat表示,多年來,TPU一直是推動領先基礎模型(包括Gemini)運作的核心,第8代TPU將在訓練、服務及智能代理工作負載中實現規模、效率和功能的重大提升。他說,在這個AI代理時代,模型必須能推理解決問題、執行多步驟流程,並從自身行為中反覆學習。這對基礎設施提出全新要求,TPU 8t和TPU 8i是與Google DeepMind合作設計,專為應對最嚴苛的AI工作負載並適應不斷演進的模型架構所打造。
TPU設定了機器學習超級運算多項關鍵組件的標準,包括自訂數值運算、液態冷卻、自訂互連等,而第8代 TPU是逾十年研發的結晶。最初TPU設計背後的關鍵理念至今依然成立,透過自訂及共同設計矽晶片與硬體、網路和軟體(包含模型架構和應用需求),能帶來顯著提升的能效與絕對運算效能。
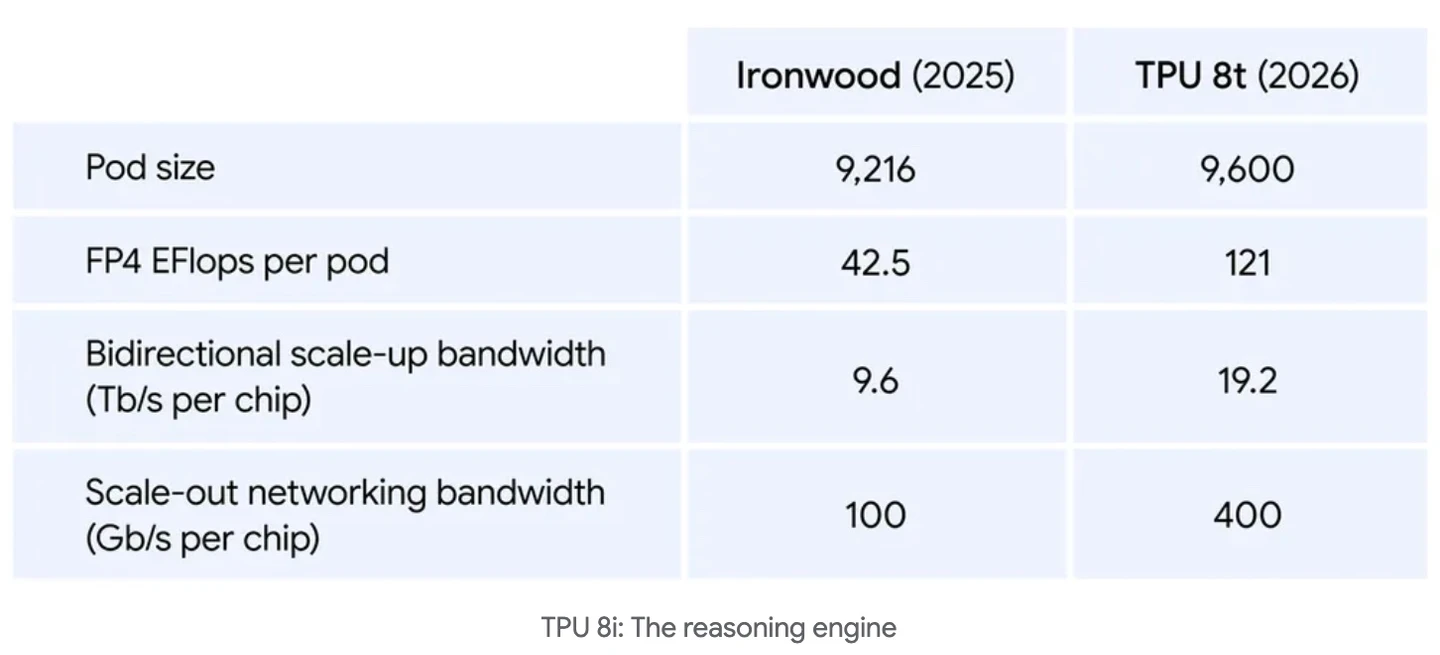
TPU 8t設計上著重較高的運算吞吐量及更多的擴展頻寬
TPU 8t在巨量、高運算強度的訓練工作負載中表現出色,設計上著重較高的運算吞吐量及更多的擴展頻寬。TPU 8i則具備更高的記憶體頻寬,能處理對延遲極為敏感的推論工作負載,這在大規模代理間的互動中尤其重要,因為即使微小的效率不足都會放大影響。值得一提的是,兩款晶片皆能執行多種工作負載,但專精設計能大幅提升效率與效能。
TPU 8t是訓練的強力引擎,TPU 8t的設計目標是將前沿模型的開發周期從數月縮短至數周。通過在最高計算吞吐量、共享記憶體和晶片間頻寬與最佳功耗效率及有效計算時間之間取得平衡,Google打造了一個系統,相較於上一代,每個運算單元的計算效能提升近3倍,促進更快速的創新,確保客戶繼續引領產業腳步。
規模化:單一TPU 8t超級叢集現在可擴展至9600顆晶片與兩拍字節(PB)的高頻寬共享記憶體,晶片間頻寬達上一代的兩倍。此架構提供121 ExaFlops 的計算能力,允許最複雜的模型利用單一且巨大的記憶體池。
最大化利用率,結合10倍更快的儲存存取速度,以及利用 TPUDirect 技術直接將資料拉入TPU,TPU 8t有助於確保端到端系統的最大化利用率。
近線性擴展:搭配新一代的Virgo網路,以及JAX和Pathways軟體,TPU 8t可在單一邏輯叢集中實現接近線性的擴展,最多可達100萬顆晶片。除了原始性能之外,TPU 8t亦設計以達到超過97%的「有效產出率」(goodput),即有用且生產性計算時間的衡量標準,這得益於一套全面的可靠性、可用性與可維護性(RAS)功能。包括跨越數萬晶片的即時遙測、自動檢測並在不中斷工作的情況下繞過故障的晶片間通訊連結,以及光路切換(OCS)技術,可在無人干預下重新配置硬體以應對故障。
每一次硬體故障、網路延遲或檢查點重啟,都是叢集無法訓練的時間,而在前沿規模的訓練中,每一個百分比點的損失,都可能意味著數天的實際訓練時間。
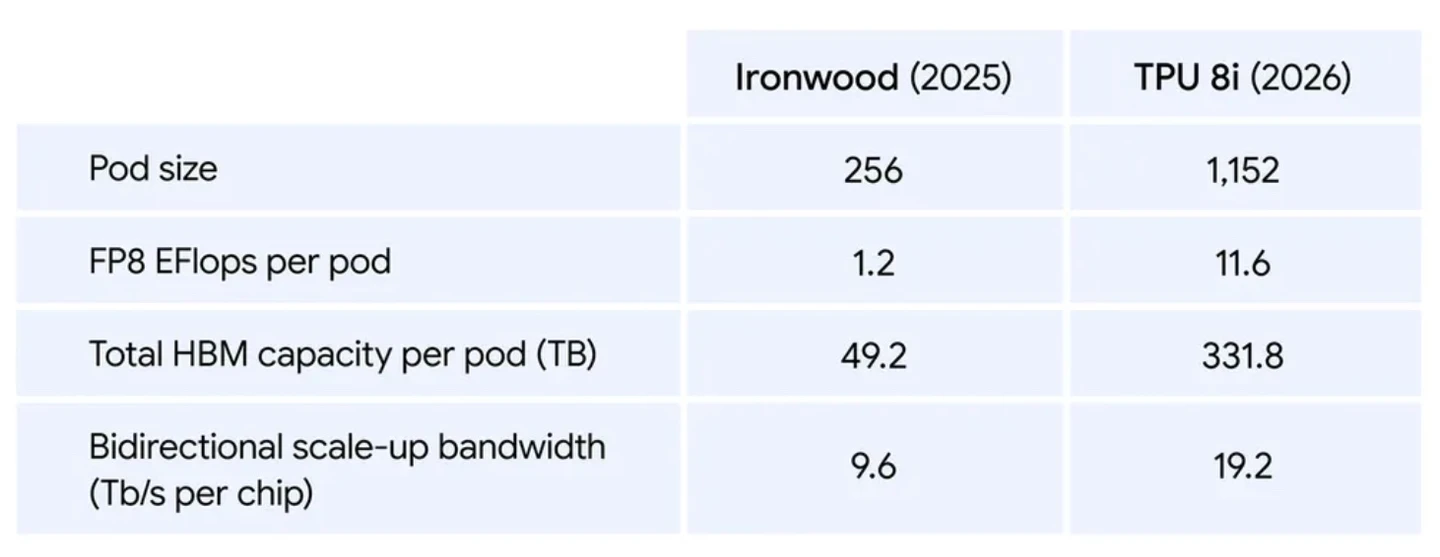
TPU 8i設計用於處理許多專業代理之間複雜、協作且反覆的工作
在智能代理時代,使用者期望能夠提出問題、委派任務並獲得結果。TPU 8i設計用於處理許多專業代理之間複雜、協作且反覆的工作,這些代理經常「蜂擁」在一起,通過複雜的流程為最具挑戰性的任務提供解決方案和洞見。Google重新設計了系統架構,通過四項關鍵創新消除了「候場效應」:打破「記憶牆」:為了避免處理器閒置,TPU 8i配備了288GB 高頻寬記憶體與384MB的片上SRAM是上一代的三倍,將模型的活躍工作集完全保存在片上。
Axion驅動效率提升:將每台伺服器的物理CPU主機數量加倍,並採用我們自訂的Axion Arm架構CPU。通過使用非一致性記憶體架構(NUMA)來隔離,Google優化了整個系統以實現卓越效能。
擴展專家混合模型(MoE):針對現代的 Mixture of Expert(MoE)模型,將互連(ICI)頻寬加倍至19.2 Tb/s。採用全新的Boardfly架構,將最大網路直徑縮小超過50%,確保系統作為一個緊密結合、低延遲的單元運行。
消除延遲:Google新型片上集體加速引擎(CAE)卸載全球操作,降低片上延遲高達5倍,將延遲降到最低。
性價比較上代提升80%
Amin Vahdat指出,這些創新使得性能成本比上一代提升了80%,讓企業能以相同成本服務近兩倍的客戶量。
為Gemini共同設計,開放給所有人使用這款第8代TPU也是Google共同設計理念的最新體現,每一項規格都旨在解決AI最大的挑戰。Boardfly 拓撲結構是專門為當今最強大的推理模型的通信需求而設計。TPU 8i的 SRAM容量是依據推理模型在生產規模下的KV快取需求量身打造。
Virgo Network網絡架構的帶寬目標是根據兆參數訓練的並行需求而制定的。這是第一次兩款晶片都搭載了Google自家的基於ARM架構的Axion CPU主機,能夠針對整個系統進行優化,而不僅僅是晶片本身,以提升性能與效率。



兩個平台均原生支持JAX、MaxText、PyTorch、SGLang 與vLLM,這些是開發人員已在使用的框架並提供裸金屬存取,讓客戶能直接訪問硬體,無需虛擬化的開銷。開源貢獻,包括MaxText的參考實現和用於強化學習的Tunix,搭建了從功能到生產部署的關鍵路徑。

TPU 8t與TPU 8i的每瓦性能比上一代提升最多兩倍
為大規模電力效率而設計,在當今的資料中心,電力而不僅僅是晶片供應,是限制性因素。為了解決這點,優化整個堆疊的效率,採用整合式電源管理,根據實時需求動態調節電力消耗。TPU 8t與TPU 8i的每瓦性能比上一代Ironwood提升了最多兩倍。但在Google,效率不僅是晶片層級的指標,更是從矽晶片到資料中心的系統性承諾。例如,將網路連接整合到同一晶片上的計算單元,有效降低了在TPU組合體間搬移數據的電力成本。甚至Google的資料中心也與TPU共同設計。
Amin Vahdat提到,Google在硬體和軟體上創新,使資料中心在相同電力單位下的計算能力比5年前提升6倍。TPU 8t與TPU 8i延續了這條發展軌跡。兩者均支援Google第四代液態冷卻技術,維持空氣冷卻無法達到的高性能密度。由於Google擁有從Axion主機到加速器的完整堆疊,能以獨立設計主機與晶片無法實現的方式,優化系統層級的能源效率。
代理時代的基礎設施,每一次重大的計算轉變都需要基礎設施的突破,代理時代也不例外。基礎設施必須進化,以滿足自主代理在持續的推理、規劃、執行和學習循環中運作的需求。
TPU 8t和TPU 8i是Google對此挑戰的回應:兩種專門的架構,旨在重新定義AI的可能性,從打造最強大的AI模型,到完美協調的代理群,再到管理最複雜的推理任務。這兩款晶片將於今年晚些時候普遍供應,並可作為Google AI超級電腦的一部分使用。該超級電腦將專用硬體(計算、儲存、網路)、開放軟體(框架、推理引擎)以及靈活的使用方式(協調、叢集管理和交付模式)整合成統一的堆疊。




















